
Cell values as rows in a spreadsheet
Posted: 2014-04-17 Filed under: academic | Tags: Cell values, gnumeric, sort, spreadsheet Leave a commentI have some spreadsheet data where the first column lists the position of a certain amino acid within a protein. There are many amino acid sites that are skipped, therefore the rows do not follow the actual, uninterrupted, amino acid sequence. I use Gnumeric, and the resulting list looks like that:

I want the program to insert empty rows between the non-consecutive amino acids — similarly to the gaps in a multiple sequence alignment. This can be done in a relatively straightforward way:
- Go to the end of your data, select an empty cell and start enumerating the column downwards consecutively until reaching a value that equals or surpasses the last amino acid number of the protein:

- Then, select the columns that need to be sorted:
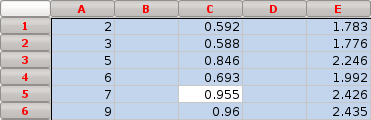
- Sort everything. This can be done from Data > Sort, or directly from the toolbar which will sort the data automatically by the first column:

- Now data will be sorted and the missing numbers of column A will be inserted in between the original data. The previously existing rows will be paired with empty ones that share the same value of column A:

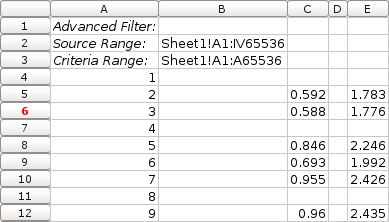
- To remove the repeating rows, go to Data > Filter > Advanced Filter, set Criteria range to be listed by column A and check Unique records only. This will eliminate empty duplicates:

- The result is as follows:
This is it! Now just cut and paste! :)
